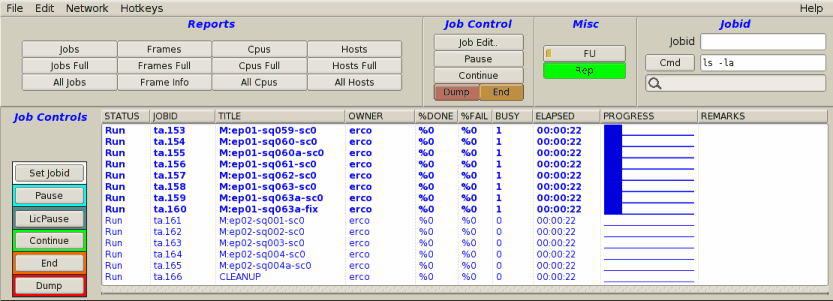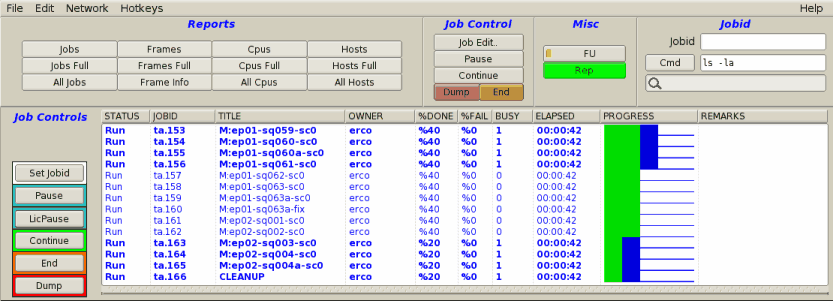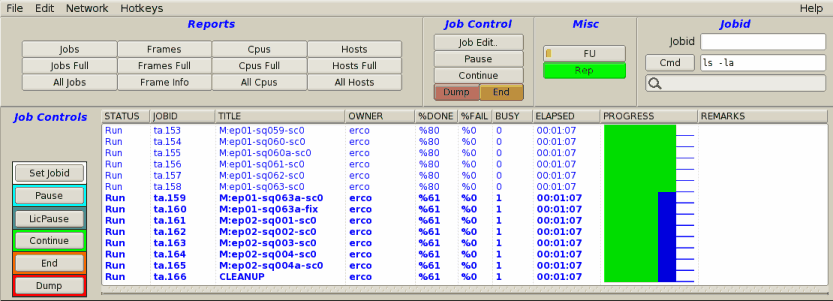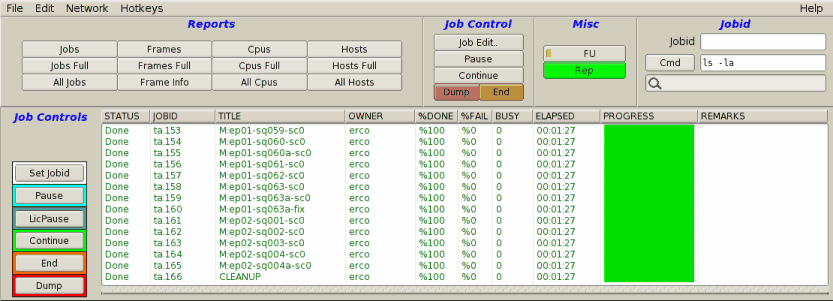
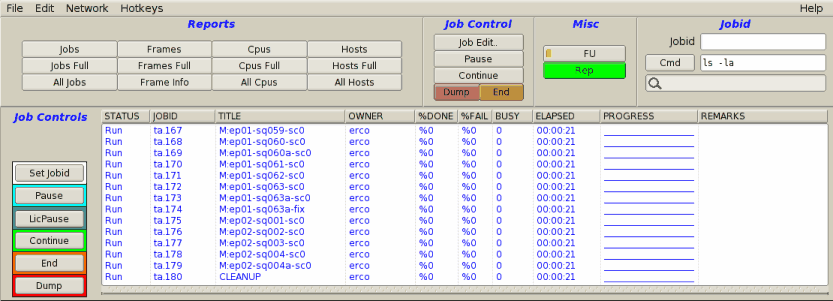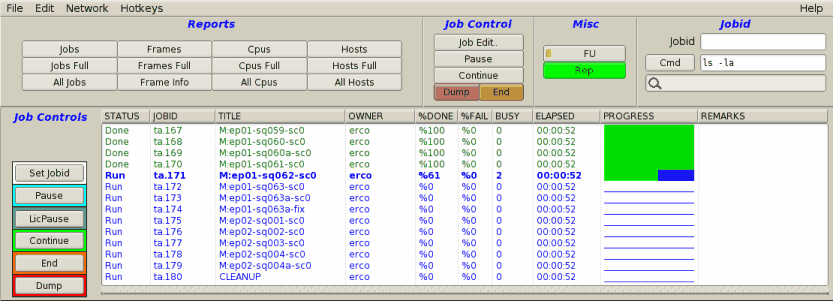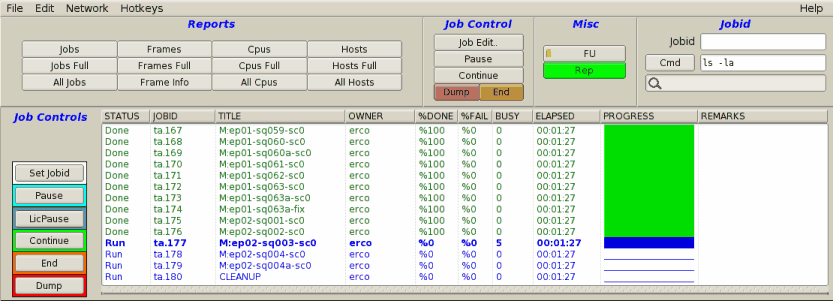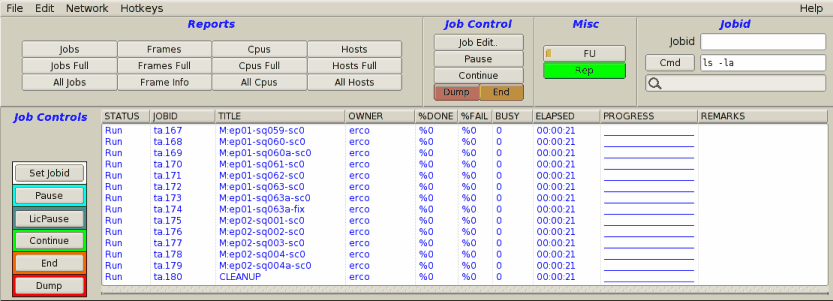
|
To use rush effectively, assign jobs with some cpus at high priority,
and some at low. This is called 'staircasing' the priorities, because
when you graph it out, it resembles a staircase:
____________________________________________________________________________
| |
| +any=5@800k |
P 200-| _________ |
r | | | | | | | |
i | | | | | | | +any=10@100 |
o 100-| | | | | | |_________________ |
r | | | | | | | | | | | | | | | | |
i | | | | | | | | | | | | | | | | +any=20@1 |
t 1-| | | | | | | | | | | | | | | |_______________________________________ |
y | |_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_|_| |
| |
|____________________________________________________________________________|
| | | |
0 5 15 35
T o t a l C p u s R e q u e s t e d
Job Requested: _
+any=5@800k |
+any=10@100 |-- 35 total
+any=20@1 _|
Most companies find they only need two specifications per job;
a high priority request for cpus (+any=5@800k) and a low priority
request (+any=20@1).
This way, if someone else submits with similar priorities, each job
will at least get 5 procs each (due the 5 at high priority), as the
high priority requests will take precedence over the low priority cpus.
This ensures everyone gets at least 5 high priority cpus. The only problem
is if the network is completely saturated with high priority frames, in which
case you're probably needing more machines. For the 'high' priority requests,
a good rule of thumb is to use a cpu cap (=5) that is around 1/10th the number
of cpus on your farm.
So if you have a 10 host farm use =1@800, on a 50 host farm use
=5@800, on 100 use =10@800, etc. Use smaller cpu cap values if there
are more jobs.
If all jobs use the same requests, there should be a balance. If one
job needs a few more cpus than others, just make the high priority
cpu cap a little higher, so instead of =5, use =8.
There are basically two ways to use "staircased" priorities; 'Passive'
and 'Aggressive'.
Staircased Priorities: Passive
If everyone submits with:
+any=2@800
+any=50@1
..then they'll all get at least =2 cpus @800 high priority,
and the rest up to =50 procs @1 low priority.
The idea here is each job asks for any 2 processors at high priority,
and the rest at low.
But if the network is saturated with jobs, then a new guy
submitting won't be able to get a frame running until one of
the running frames finish. If the renders are long, that might
be a while to wait.
Staircased Priorities: Aggressive
A more aggressive job wouldn't want to wait around for low
priority frames to get done. They want the job to take those
high priority frames right away.
This is where the 'k' flag becomes useful (Kill) on the high priority
submission, so that it bumps lower priority frames out of the way,
instead of waiting for them to finish, so the job can kick in those
high priority frames without waiting.
So instead, if everyone 'that's in a hurry' submits jobs with:
+any=2@800k -- note the 'k'
+any=50@1
..then that ensures that if the network is mostly saturated with
low priority renders, this new submit will bump at least two low
priority renders to get a couple at high priority.
Note that the above will only bump for two procs, the rest will
wait in round robin.
High priority renders won't bump other high priority renders
(as long as the 'high' numbers are all 100k).
Feel free to ask questions, but first check out the docs above
to get an understanding of how the priority stuff works.
You may find you want to increase or decrease the number after
the '=' sign as needed.
The priority numbers themselves are relativeistic; there's no magic
about the numbers '100' or '1', they could be '499' and '500'. Just
as long as the entire shop agrees on what numbers are considered
'high priority' and what numbers are considered 'low'.
It is recommended to think of numbers above 99 as 'high', and 99 and
lower as low. This is arbitrary from the software's point of view,
since values are relativistic. But using these arbitrary values
leaves some elbow room in both directions.
All companies reserve 999k priority for 'it must go through' jobs.
For instance, submitting a job with '+any=3@999k' will ensure 3 frames
rendering as soon as the job is submitted. And of course, to 'take over'
the entire network, nasty this would be: +any=100@999k, which would kill
everything running (requing the frames of course) and pushing the current
job through the pipe.
|