FIFO (First In/First Out) scheduling is a scheduling option
that was added to Rush 102.42a9. "Round Robin" is normally
the default scheduling algorithm used by Rush, but the systems
administrator can change this with the rush.conf file's
"sched fifo" command.
FIFO and Round Robin are mutually exclusive scheduling techniques;
the entire farm will use either one or the other. These are used
to decide which job gets an available cpu when priorities of jobs
are otherwise equal.
For instance, when a cpu becomes available, if all jobs being
considered are of equal priority, then one of these schemes
is used to decide "who's next" to break the tie.
Comparing the two scheduling schemes:
|
Round Robin Scheduling (default) will render job's frames
using "fairness"; whenever a processor becomes available, each job
will get a chance to render a frame on that processor. In the case
of three jobs A,B and C, all rendering at the same priority,
each time a cpu becomes available, it first works on a frame from
job "A", then job "B", then job "C", then back to "A". This repeats
until the jobs are completed.
With Round Robin scheduling, jobs of equal priority
finish more or less at the same time. Example:
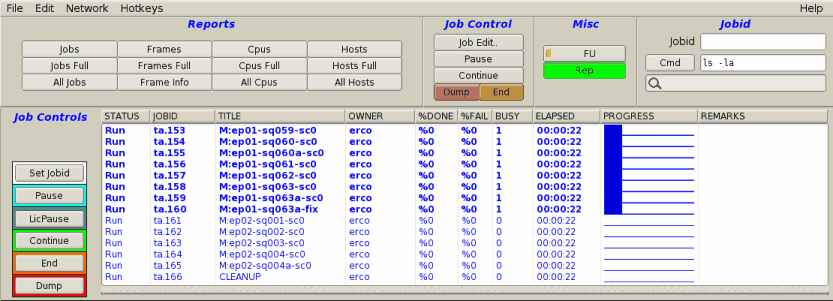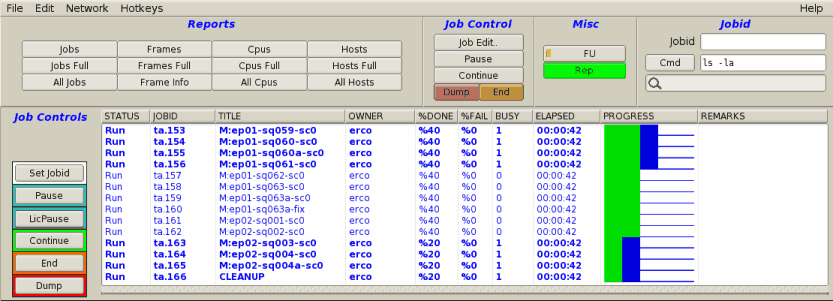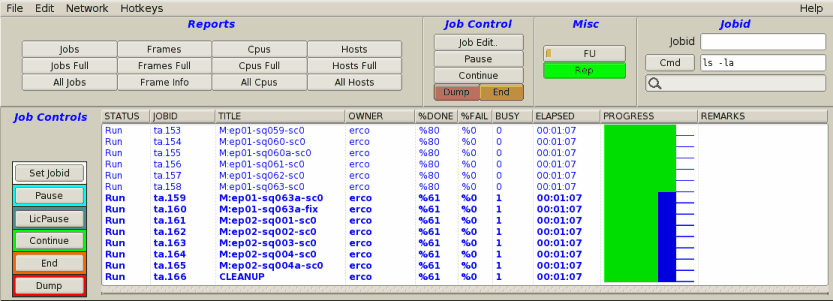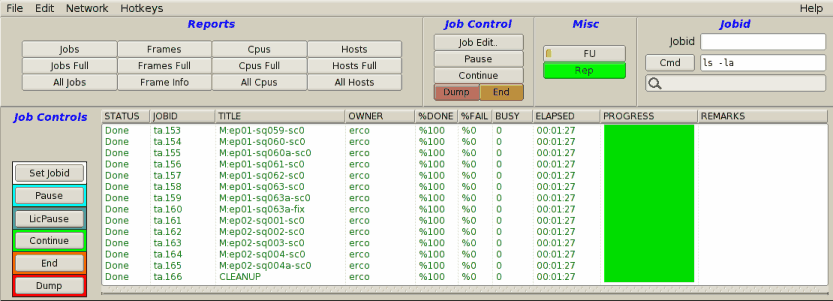
An example of round robin scheduling.
Note the PROGRESS field shows the queue is moving
through jobs concurrently, more or less from left-to-right.
|
|
|
FIFO Scheduling will render job's frames in the order the
jobs were submitted, one job at a time; whenever a processor
becomes available, it will continue to work on the oldest job
until that job can render no more frames. Then the processor
will start working on the next job. So in the case of three jobs
A,B and C, submitted in that order and rendering at the same priorities,
each time a cpu becomes available, it continues to work on frames
from job "A" until that job finishes, then works on frames from job "B",
then "C".
With FIFO scheduling, jobs of equal priority finish more or less
in the order they were submitted. Example:
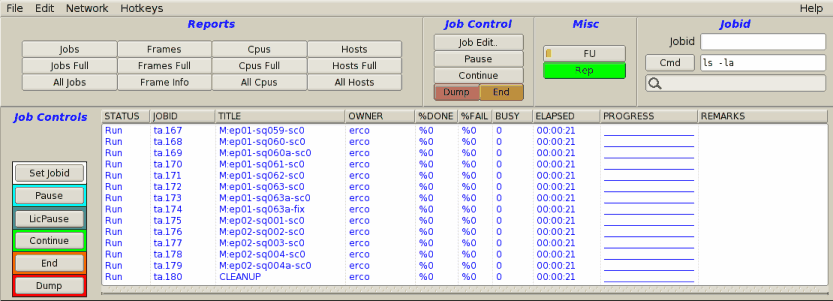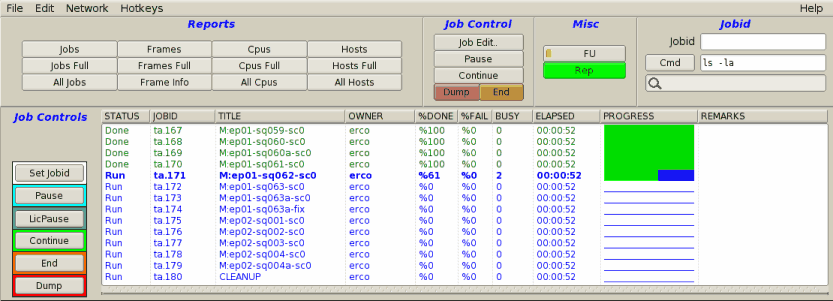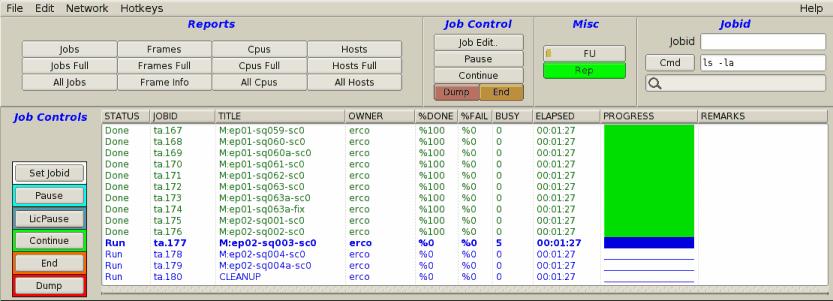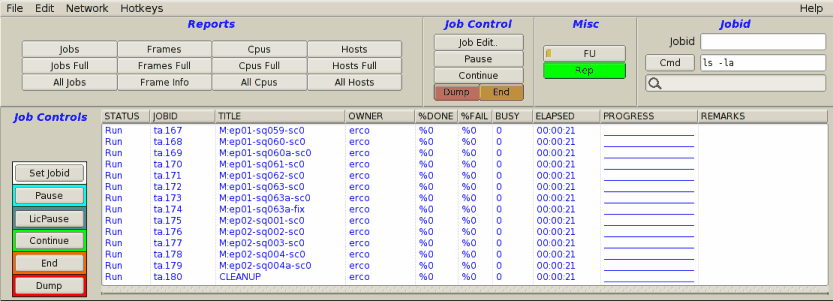
An example of FIFO scheduling.
Note the PROGRESS field shows the queue moving through
jobs from top-to-bottom.
|
|
FIFO means the job "first in" gets the cpus it wants, so that job
becomes the "first out" (ie. first done), and all all other jobs
submitted after that have to wait in line.
FIFO is useful if users don't mind waiting in line, and don't
care about not getting /any/ cpus until their job is next in line,
where it then "takes over" the entire farm.
Since priority always takes precedence, FIFO scheduling can
only be clearly seen when all jobs are at the same priority.
However, it is useful to mix priorities and FIFO, to create
different FIFO 'tiers'.
Using "Pure" FIFO
The idea of FIFO is to prevent users from having to be concerned
about prirority, and it's just a 'first in/first out' queue.
So for a pure FIFO queue, everyone should submit with the
*same priority*, and not uses mixes (eg. NOT use Priority Staircasing)
So if everyone submits their job with e.g.
..then all jobs will line up in a row (as shown in the above
screenshots), each waiting for the job that was submitted
in front of them to finish.
Using FIFO With Priority
There's always situations where 'pure FIFO' is too simple;
there's always someone who's job suddenly becomes very important,
and even though their job is last in the queue, it needs to get *some*
cpus right away to preview a few frames, or perhaps it needs *all* cpus
because a client is waiting.
In such cases, in addition to the user's +any=50@100
FIFO cpu request, they can add a few cpus at a higher
priority, say +any=4@200.
Since all the other jobs are @100, this job will "win"
up to 4 cpus @200 priority from the other FIFO jobs
because of the higher priority request.
Remember that "higher priority always wins", so those
4 cpus @200 means they'll get some cpu right away,
while their other cpu request for +any=50@100 will
continue to wait in FIFO order.
In this way a job can still 'mostly' follow FIFO rules,
with just a few higher priority cpus being the exception.
Or, it can ask for *ALL* cpus at high priority to take over
the entire network right away. Use this for very critical
jobs that need to get done right away, or can get done
very quickly.
If more than one job is configured with high priority,
they will fight amongst each other using FIFO precedence,
before anything is done with the lower priority FIFO queue.
This would effectively create two 'tiers', or two FIFO queues.
So with this, you can make multiple FIFO queues.
Say there's two projects: